Anders Hesselbom
Programmerare, skeptiker, sekulärhumanist, antirasist.
Författare till bok om C64 och senbliven lantis.
Röstar pirat.
Hur får man bra ljud i en podcast?
2022-04-24
Podcastproduktion sker i flera steg. Man ska rigga utrustning, göra en soundcheck, spela in podcasten, klippa den, montera och mastra den och publicera den. Jag har redigerat ljud i vågformseditorer sedan tidigt 1990-tal och poddat sedan 00-talet. Jag har bl.a. varit inblandad i produktionen av Skeptikerpodden, Radio Bulletin, Stulet gods, Radio Houdi, Generation YX och Samtal. I och med att jag sysslat en del med montering och mastring, och får ibland frågan om jag kan bistå. På grund av arbetsbelastning så tackar jag alltid nej, men det är inte speciellt svårt att göra en mastring på egen hand.
För att resultatet ska bli riktigt bra, måste inspelningen ha gjorts korrekt. Inspelningsvolymen får inte vara för låg, för då kan man få problem med brus. Inspelningsvolymen får absolut inte vara för hög (“clipping” – ej att förväxla med klippning), för då blir vågformen helt enkelt förstörd. Mikrofonerna bör vara någorlunda bra, och helst vill man inte ha mikrofonen för nära munnen eller andas direkt in i mikrofonen. Har man ingen bra inspelningsstudio så finns det risk att mikrofonen plockar upp rumseko och att ljudet därför blir lite burkigt. Många brukar lösa detta genom att sänka inspelningsvolymen och prata närmre mikrofonen. Det fungerar, men det introducerar ett annat problem, nämligen att ljudet låter onaturligt, som om någon pratar rätt in i ditt öra. Utan tillgång till professionell utrustning får man göra vad man kan.
Tänk också på att använda puffskydd (vissa säger “pop-filer” numera) för att minska risken att man skapa oljud genom att andas på mikrofonens membran.
Om fler än en person pratar i podcasten, så är det bra om dessa ligger i var sin fil under mastringen. Särskilt ljudnivåerna är bra att kunna styra individuellt.
Mastringsarbetet görs i speciella program för vågformseditering. Man arbetar alltså med redan renderade ljudfiler, direkt mot vågformen. Dessa program kan benämnas på lite olika sätt, men wave editor är ganska vedertaget. I programmet öppnar du upp det klippta råmaterialet du fått från klipparen, där varje kanal är en fil, och ditt ansvar är att:
- Harmoniera bitdjup och samplingsfrekvens
- Korrigera nivåer
- Eventuell brusreducering och eventuell frekvensutjämning (equalization)
- Montering av röstkanaler
- Komprimering
- Eventuell extra klippning
- Montering av signaturmelodier
- Slutrendering
Harmoniera bitdjup och samplingsfrekvens
Eftersom vi jobbar direkt i vågformen så får vi ingen hjälp av mjukvaran att hantera om ljudfilerna har olika bitdjup. Bitdjupet anger hur många möjliga impulsnivåer varje samplingspunkt har, och ett högre tal är bättre. 8-bit, 16-bit eller 24-bit är ganska vanligt. Professionella ljudproducenter brukar arbeta med 24-bit och leverera en slutprodukt som är 16-bit, men arbetar man med podcasts så räcker det ofta att kontrollera att ingen inblandad ljudfil är sämre än 16-bit.
När det gäller samplingsfrekvens, som anger samplingspunkternas täthet, är 44,1 KHz lämplig, men vissa inspelningsprogram kan leverera filer på 22,05 eller 48 KHz. Högre är bättre även här. Då behöver du göra en resample till 44,1 KHz, som är fullt tillräckligt för att mastra en podcast. När alla filer har samma bitdjup och samplingsfrekvens är detta steg färdigt.
Korrigera nivåer
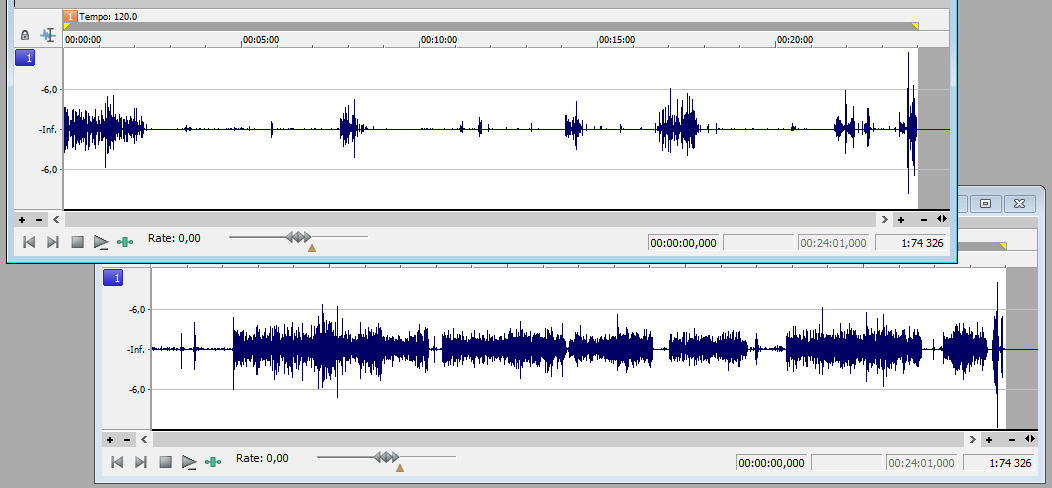
Det är bra om samtliga medverkande har samma impulsstyrka, till den grad man kan styra det. I exemplet på bilden har vi två filer. Den ena filen innehåller en person som pratar i en mikrofon, och den andra filen innehåller två personer som delar på en mikrofon. Båda är lite för låga för att det ska vara passande, men det är lättare att göra ett bra jobb om ursprungsimpulsen är lite för låg än lite för hög.
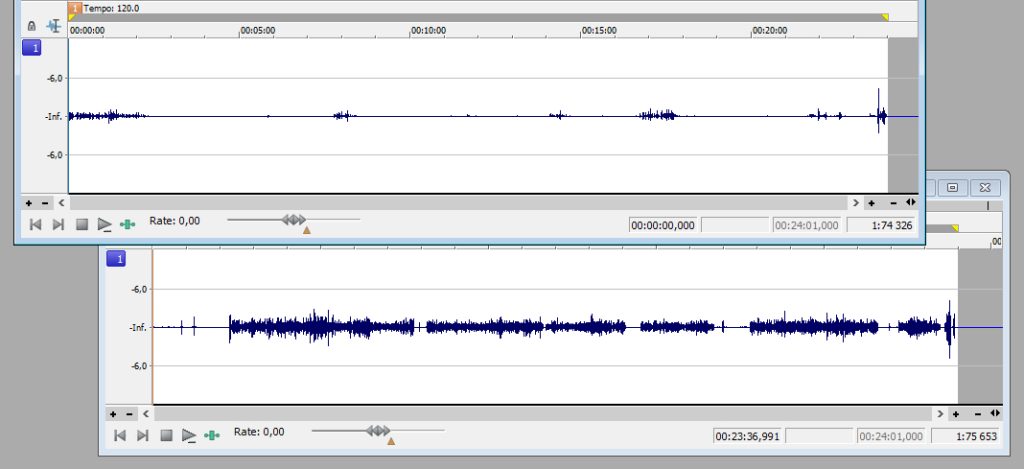
Den ena kanalen (överst) är lite svagare än den andra, så båda behöver förstärkas, men den övre lite mer än den undre. Notera att något sticker ut mot slutet av filen. Om den biten ska vara med, bör inte volymen höjas mer än att den biten fortfarande har god marginal till impulsens maxvärde. Det kan i värsta fall vara ljud i båda kanalerna samtidigt där, och då finns det risk att clipping uppstår när filerna slås samman.
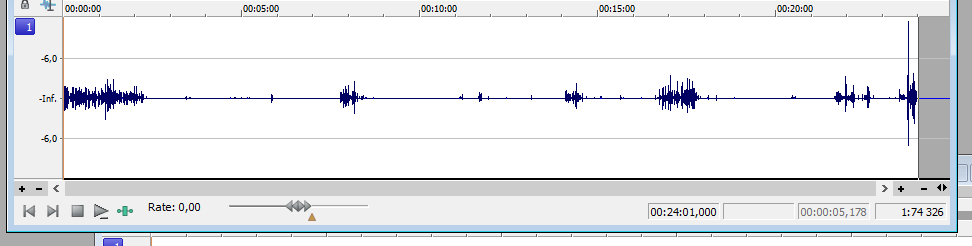
Innan jag höjt volymen tillräckligt på första kanalen, inser jag att detta kommer att slå i taket. Efter att ha zoomat in, kan jag konstatera detta är ett skratt som ska vara med i slutprodukten. För att få upp volymen till önskad nivå, måste jag manuellt först sänka volymen på det skrattet. Jag gör samma sak i båda filerna, om än lite mindre i den andra. Detta är jag nöjd med:
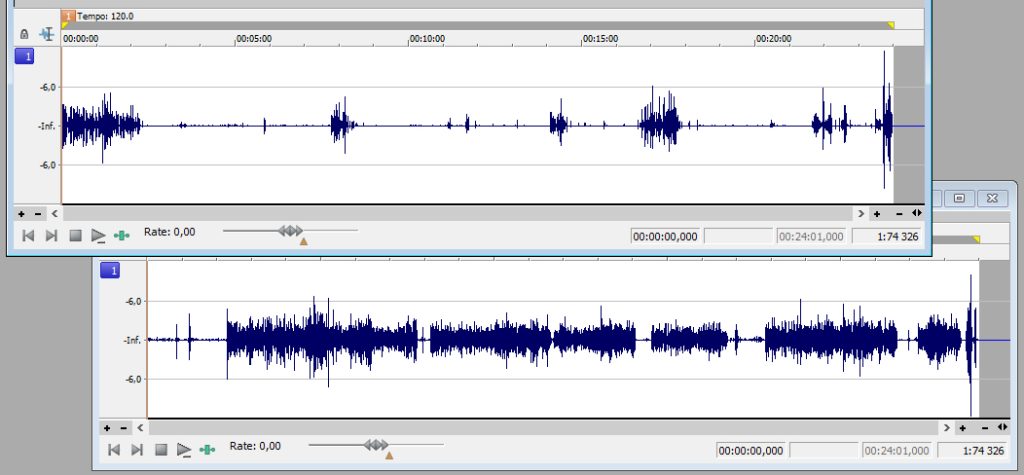
Eventuell brusreducering och eventuell frekvensutjämning
Det ser ut att hända en del saker, särskilt i den undre filen, mellan pratet. Är det störande ljud som måste tas bort (funktionen “mute”)? Skiljer de två filerna varandra åt i frekvensomfång? Det behöver rättas till med en equalizer. Innehåller någon fil mer toppar och dalar än den andra, eller är någon fil mer fyrkantig (kanjonisk) än någon annan? Den med många toppar och dalar kanske behöver ha lite kompressor redan i detta steg. Det är bra om filerna liknar varandra.
Montering av röstkanaler
När filerna är tillräckligt lika varandra, ska de slås samman till en fil. Den funktionen brukar heta “mix” i denna form av program. Nu ser vi första versionen av den fil som är resultatet av vårt arbete.
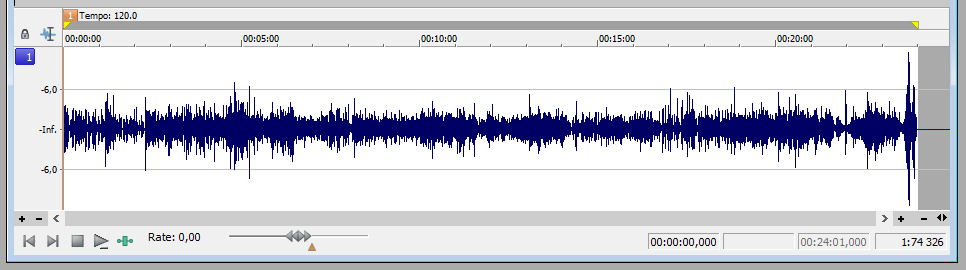
Komprimering
Nu vill vi att volymen ska vara jämn och stark, så att alla detaljer hörs, även när det pratas tyst, och så att inte lyssnaren får hörselskador av något häftigt skratt. Vi vill lägga kompressor på ljudet. I en vågformseditor brukar denna hantering kallas compression. Jag brukar gå fram ganska försiktigt, till en början. Är man för snål, kan det bli svårt att höra alla detaljer, och det kan komma höga överraskningar för lyssnaren. Tar man i för mycket, låter ljudet onaturligt, som om någon står mycket nära dig och pratar.
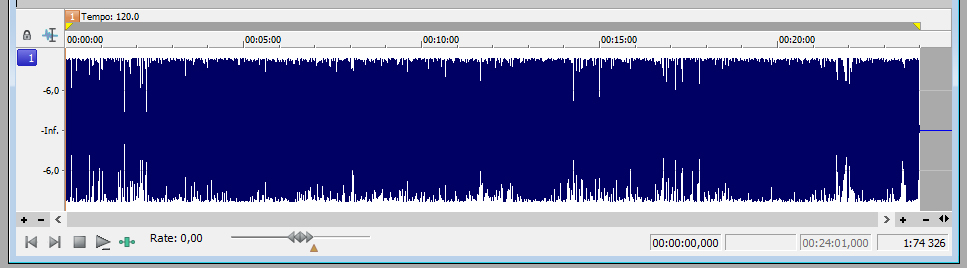
Det där höga skrattet på slutet sticker inte längre ut i ljudstyrka, utan i att den som skrattar tillfälligt låter lite “närmre” lyssnaren. Dessutom är fraser som yttrats lite försiktigt i bakgrunden, nu fullt hörbara.
Eventuell extra klippning
Det är bra att zooma in och titta igenom vågformen efter omotiverat långa pauser, eller onödigt många ticks, som t.ex. “ööhhh…” eller liknande. Ta inte bort allt, bara några stycken. Korta inte gärna ner pauser utan att säkerställa att du inte klipper i andetag, ta hellre bort någon omotiverad paus då och då.
Montering av signaturmelodier
Kontrollera att signaturmelodierna ligger strax under pratet i volymstyrka, och mixa in musiken först, sist eller var det ska ligga. Tänk på att om musik och prat ska gå in i varandra, så blir den totala ljudstyrkan högre där detta sker.
Slutrendering
För en podcast brukar man välja att rendera slutresultatet som en MP3-fil, med en bithastighet på 128 kilobit per sekund (Kbps), i 16-bitars mono. Det ger en bra kompromiss mellan filstorlek och ljudkvalitet.
När man har fått rutin på denna process brukar det inte vara mer än en halvtimmas arbete per podcastavsnitt, innan du kan lämna resultatet vidare till den som ansvarar för publicering. Lycka till!
Categories: General
One response to “Hur får man bra ljud i en podcast?”
Leave a Reply
En kopp kaffe!
Bjud mig på en kopp kaffe (20:-) som tack för bra innehåll!


Följ mig

|

|

|

|

Underbart! TACK!